강남에서 만나는 자연 그대로의 숲, 대체 불가능한 숲과 집의 가치 - 르엘 어퍼하우스
.jpg&w=3840&q=75)
로펌 속으로
와이케이
재택근무/원거리 근무에 대한 근태관리와 인사노무 자문
인터넷
2024-04-19
태평양
정년연장형 임금피크제의 유효성을 확인한 판결
인터넷
2024-04-18

화우
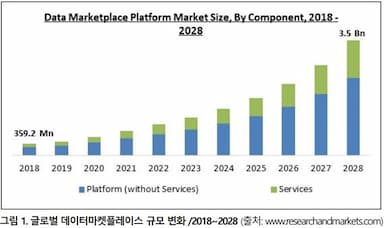
데이터 거래산업과 정보보호
인터넷
2024-04-17
대륙아주
IP 이슈리포트 - 메타버스에서의 저작물 이용방법과 유의사항
인터넷
2024-04-17
바른
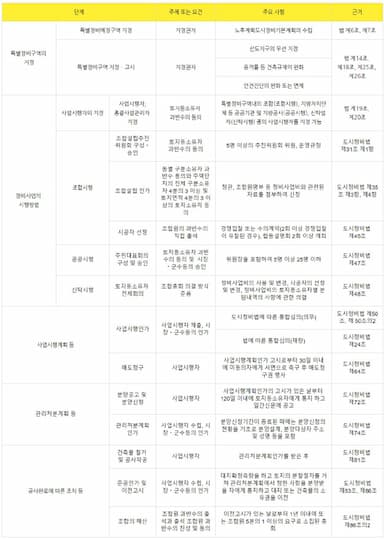
‘노후계획도시특별법’ 본격 시행… 선도지구 연내 지정될 듯
인터넷
2024-04-17
세종
개인정보보호위원회, 「해외사업자의 개인정보 보호법 적용 안내서」 발간
인터넷
2024-04-17
화우
생성형 AI의 국제 규제 동향
인터넷
2024-04-13
.jpg&w=384&q=75)
태평양
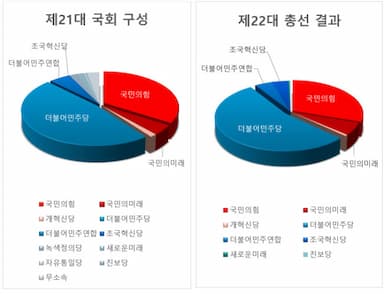
총선결과 분석 및 주요 분야 정책 전망
인터넷
2024-04-12
와이케이
가상자산을 이용한 사기 범죄의 유형과 피해 방지를 위한 유의사항
인터넷
2024-04-12
지평
[헌법·행정·규제대응] 과세처분과 당연무효 판단기준
인터넷
2024-04-09
1950년 창간 법조 유일의 정론지

법인명
(주)법률신문사
대표
이수형
사업자등록번호
214-81-99775
등록번호
서울 아00027
등록연월일
2005년 8월 24일
제호
법률신문
발행인
이수형
편집인
차병직 , 이수형
편집국장
신동진
발행소(주소)
서울특별시 서초구 서초대로 396, 14층
발행일자
1999년 12월 1일
전화번호
02-3472-0601
청소년보호책임자
김순신
개인정보보호책임자
김순신